projects
Project 1: Obesity Kaggle Challenge
As the final project for my statistical models and data mining class, I collaborated with a group of other students to participate in a Kaggle competition. Competing against 44 other teams, the goal was to build the most accurate predictive model that classified individuals as “obese” or “not obese” using a dataset on Kaggle that contained over 40,000 observations with dozens of predictors at our disposal.
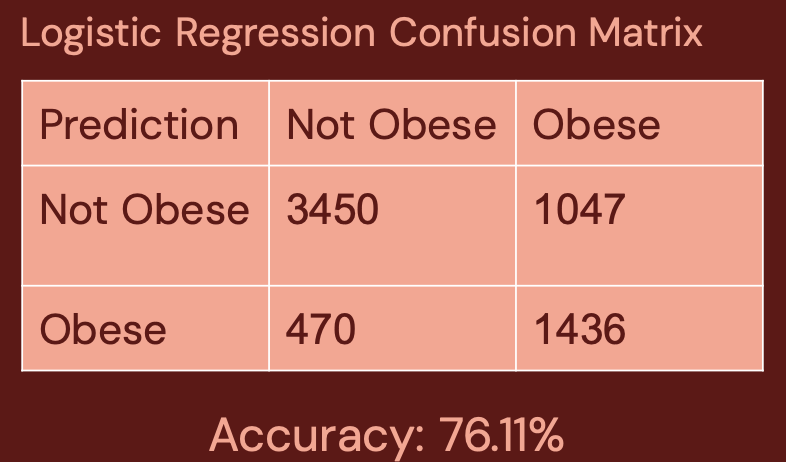
Our data had thousands of missing values, so we created three datasets that each used a different imputation method in R: missforest, mice, and amelia. The next step was to fit a logistic regression model to each of these datasets and evaluate each model’s performance. We found that the missforest imputation method performed the best with an accuracy of 76.11%.
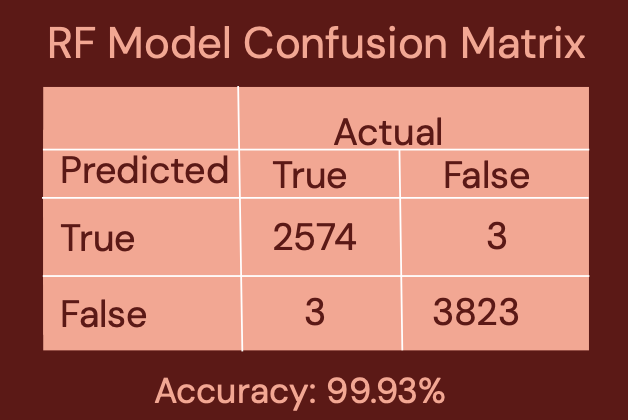
Wanting a more accurate model, we decided to turn to random forests as they tend to be more powerful despite having less interpretability. After hypertuning model parameters such as number of trees and random columns used, we finally arrived at our most accurate model, which also used the missforest imputed dataset. This model was 99.3% accurate in classifying individuals as obese or not obese, ranking 7th out of all 45 teams.
Project 2: UCLA Graduate Earnings Comparison Analysis
Working in a team, I assisted in carrying out a thorough analysis that aimed to compare and understand differences in median earnings for college graduates from UCLA with other institutions. This was a capstone project for the statistics and data science major that included directly working with external clients who were academics and analytics directors for UCLA.
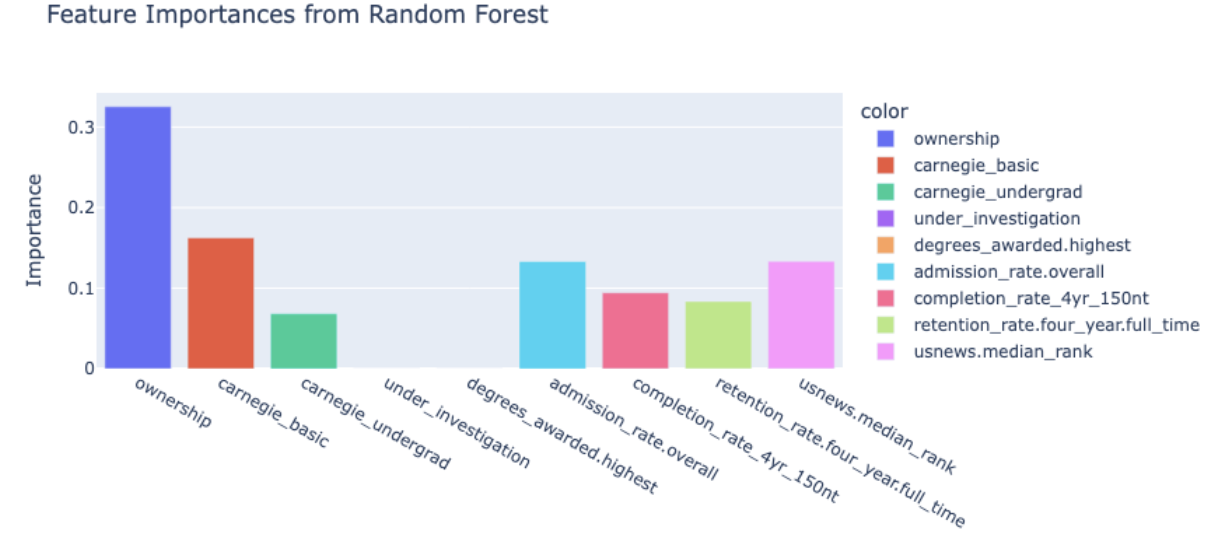
After variable selection, my team and I began by clustering our data using robust, high-end methods such as HDBSCAN to identify a similar, large enough set of universities to compare UCLA to. As we see in the variable importance plot, our clustering was primarily based on admission rate, ownership(public/private status), and Carnegie basic classification.
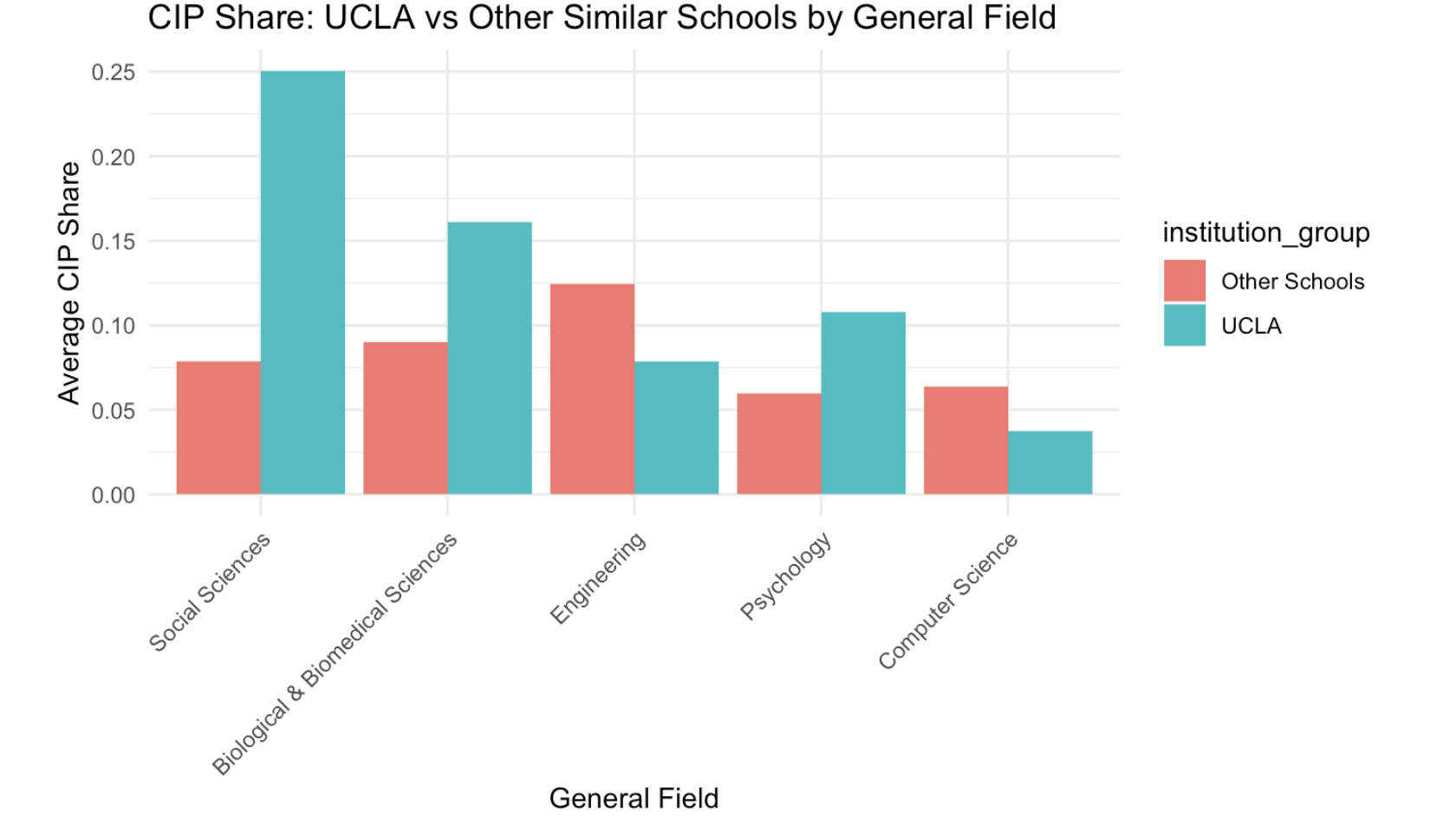
Overall, we found that UCLA graduate earnings are comfortably in the upper 20% of schools for virtually every field of study. However, in terms overall median earnings, UCLA did lag behind the most elite schools like Harvard or Yale as well as several schools in our cluster. We speculate this to be the case because liberal arts students, who typically make less money, represent a much greater proportion of the undergraduate population at UCLA compared to other schools as shown below.
Project 3: Utah Hockey Club Analytics Challenge
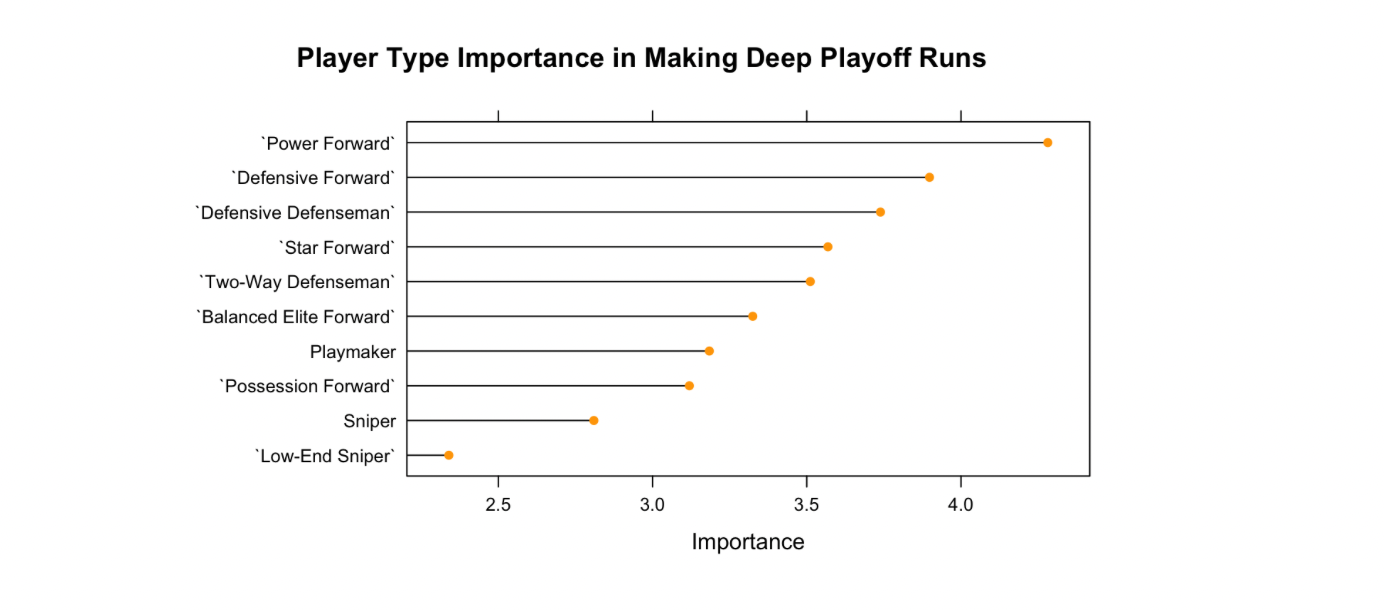
For this project, I worked independently attempted to figure out what player types in the NHL are most important to a team’s regular season and playoff success. Using team and player data over the last 15 seasons, I categorized every player on all the teams based on their individual metrics as a specific player category which included types like “Playmaker,” “Power Forward,” and “Defensive Defenseman”. With this custom dataset, I created random forest regression models to determine which player types were most important to have in order to achieve regular season and playoff success. In order to make a “deep” playoff run, which I classified as a team winning 2 rounds or more, I found power forwards and defensive forwards to be most important for a team to have.
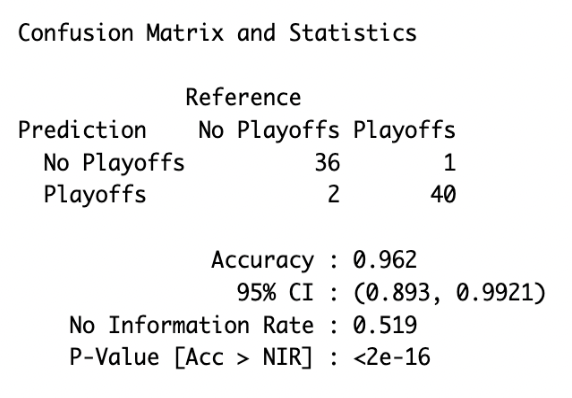
I also created a combined dataset that included the player types along with overall team metrics and used it to build a random forest classification model that predicted whether teams would make or miss the playoffs. It performed quite well with an accuracy of 96.2%.